

As a PhD student in Deep Learning, as well as running my own consultancy, building machine learning products for clients I’m used to working in the cloud and will keep doing so for production-oriented systems/algorithms. There are however huge drawbacks to cloud-based systems for more research oriented tasks where you mainly want to try out various algorithms and architectures, to iterate and move fast. To make this possible I decided to custom design and build my own system specifically tailored for Deep Learning, stacked full with GPUs. This turned out both more easy and more difficult than I imagined. In what follows I will share my “adventure” with you. I hope it will be useful for both novel and established Deep Learning practitioners.
See the earlier part of this series at:
Overview
Software & Libraries
Now we got a bare metal system, it’s time to install some software! There are a couple of really good posts on installing all the tools and libraries for Deep Learning. To make things easy, I’ve put some gists together for the occasion. It will help you to install the Nvidia CUDA drivers, as well as the kind of libraries and tools I tend to work with for Deep Learning. It is assumed that you have installed Ubuntu 14.04.3 LTS as your operating system.
1 Installing CUDA
Getting the graphical drivers to work can be a pain in the %€#. My issue at the time was that Titan X GPUs are only supported from Nvidia 346 onward, but that these drivers wouldn’t work with my specific monitor. With some xconfig modding I got it somehow to work on higher resolutions than 800x600, using 352.30 as the graphical driver.
The script installs CUDA 7.0. I chose to install the newest CUDA 7.5. While this version does offer some improvements, it also tends to be a bit difficult to get working for some libraries. If you want to be fast up and running, try 7.0 instead.
2 Testing CUDA
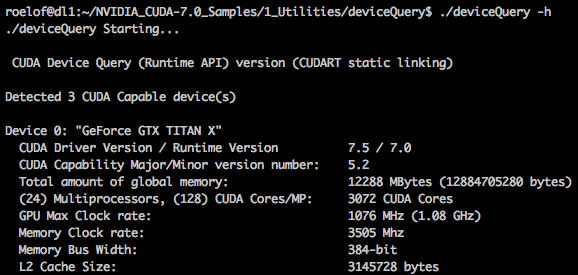
Done? Great, let’s see if the CUDA drivers work. Go to the CUDA sample directory, make them and run ./deviceQuery. Your GPUs should be shown.
3 Deep Learning Libraries
Ok final step: we’re getting to the fun part: Choosing which Deep Learning libraries to work with is a matter of personal preference, as well as domain given.
- Theano gives you the most freedom as a researcher to do whatever you want to do. You get to implement many things yourself, and in so doing gain a deep understanding of how DNNs work, but maybe not the best suited for a beginner who wants to first “play” a bit.
- Personally I’m a big fan of both Keras (main contributor: François Chollet, who just moved to work at Google) and Lasagne (team of eight people, but main contributor: Sander Dielemans, who recently finished his PhD and now works at Google Deepmind). They have a good level of abstraction, are actively developed, but also offer easy ways to plug in your own modules or code projects.
- Torch can be challenging if you’re used to Python as you’d have to learn Lua. After working for some time with Torch, I can say its actually a pretty good language to work with. Its only real big issue is that it’s tough to interface from other languages to Lua. Also for research purposes Torch will do fine, but for production level pipelines, Torch is hard to test and seems to completely lack any type of error handling. On the positive side though: It has support for CUDA, and has many packages to play with. Torch also seems to be the most widely adopted library in the industry. Facebook (Ronan Collobert & Soumith Chintala), Deepmind (Koray Kavukçuoğlu) and also Twitter (Clement Farabet) are all active contributors.
- Caffe (originally by Yangqing Jia as his PhD work), the former dominant Deep Learning framework (mainly used for Convnets) from Berkeley is still widely used and a nice framework to start with. The separation between training regimes (solver.prototxt), and architecture (train_val.prototxt) files allows for easy experimentation. I have found Caffe also to be the only framework which supports multi-GPU use out of the box. Without much hassle, one can just pass the –gpu all or –gpu <id> argument to use all available GPUs.
- Blocks is a bit more recent python-based framework. It has pretty nice separation of modules you can write yourself, and which are called “Bricks”. Especially its partner “Fuel” is a really nice way to deal with data: Fuel is a wrapper for many existing or your own datasets. It implements “iteration schemes” to stream your data to your model and “transformers” for all kinds of typical data transformations and pre-processing steps.
- neon is Nervana Systems’ Python based Deep Learning framework, build on top of Nervana’s gpu kernel (an alternative to Nvidia’s CuDNN). It is the only framework running this specific kernel, and latest benchmarks show it to be the fastest for some specific tasks.


Ready? The script below will install Theano, Torch, Caffe, Digits, Lasagne and Keras. We haven’t managed Digits before, but its a graphical web interface build on top of Caffe. It’s pretty basic, but if you’re just starting out it’s an easy way to train some ConvNets and build some image classifiers.
Where to go from here? Resources and Links
If you managed to come this far, congratulations! It’s time to play! There are many tutorials, seminars, articles, and web pages out there to get you started with Deep Learning. Some links below to get you on your way:
- The single best resource is deeplearning.net, especially the tutorial section. (On a side note: if you’re really into Deep Learning and want to do a PhD, there’s a great deep learning research groups and labs as well);
- There are multiple Deep Learning Meetup groups around the globe with interesting talks, and the kind of people you might want to interact with: Stockholm, Munich, London, Paris, San Francisco and Toronto;
- Videos from the Deep Learning Summer School in Montreal 2015;
- Nando de Freitas series of Deep Learning video lectures at Oxford;
- CS224d: Deep Learning for Natural Language Processing at Stanford, syllabus with lecture slides and links to all video recordings;
- CS231n: Convolutional Neural Networks for Visual Recognition at Stanford by Fei-Fei Li and Andrej Karpathy, course notes with lecture slides and assignments;
- A lot of Deep Learning news gets send around over the web through the Deep Learning Google+ community, as well as on Twitter under the hashtag #dlearn;
- The biggest Deep Learning Bibliography at Memkite;
- And further of course just keep checking arxiv, or a more recent project linking articles to code: GitXiv;
- Most deep learning libraries like Caffe and others have their own mailing lists or at least GitHub issues pages where discussions take place.
That’s it for now. Next time we will benchmark different numbers of GPUs and nets, and learn more about the kinds of speedups multiple GPUs can offer.